 RELAX NG Implementation Cook Book: Day 1
RELAX NG Implementation Cook Book: Day 1
$Id: Grammar1.docbook,v 1.0 2001-08-17 23:46:15-07 bear Exp bear $
Copyright © 2001 Kohsuke KAWAGUCHI
Abstract
The first day starts with the core grammar model, which will become the foundation of the entire validator.
Table of Contents
This article assumes that you have fair degree of understanding of the programming language you choose and experience of reading/writing RELAX NG schema. Within the article, DTD notation is frequently used. For example, you should be able to understand what does "foo?,(bar|zot*)" mean. "&" is used to represent the interleave combinator. Also, it is highly recommended to read the formal spec, although you don't necessarily understand it completely.
OK let's get started. In the first day, we'll develop the grammar model. This grammar model is used to internally represent RELAX NG grammars and also used to perform validation. The grammar model parallels the simplified RELAX NG grammar. Let me start off with an example. The following grammar will be represented as depicted below:
<oneOrMore> <choice> <element name="A"> <empty/> </element> <element name="B"> <empty/> </element> <text/> </choice> </oneOrMore>
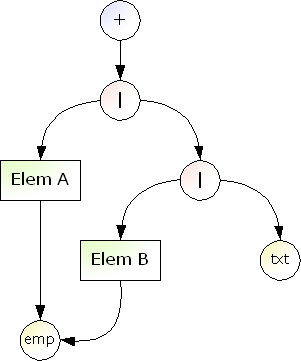 |
Circles and boxes represent objects, and arrows represent references between objects.
Symbols in circles denote the type of objects. For example, A circle with '+' sign is an object of the OneOrMoreExp class, which represents a <oneOrMore> pattern. A circle with '|' sign is an object of the ChoiceExp class, which represents a <choice> pattern. txt stands for the <text/> pattern and emp stands for the <empty/> pattern.
First, you can see that all combinators (choice,sequence and interleave) are binarized, and all other patterns are unarized(?). That is, these combinators always have two children. So if you've got A|B|text, then you'll treat it as (A|B)|text. The simplified RELAX NG grammar is also binarized in a similar way, but we'll introduce one additional rule.
As you see, a grammar is composed from these simple primitive patterns. The objective of the first day is to develop implementations for those primitives.
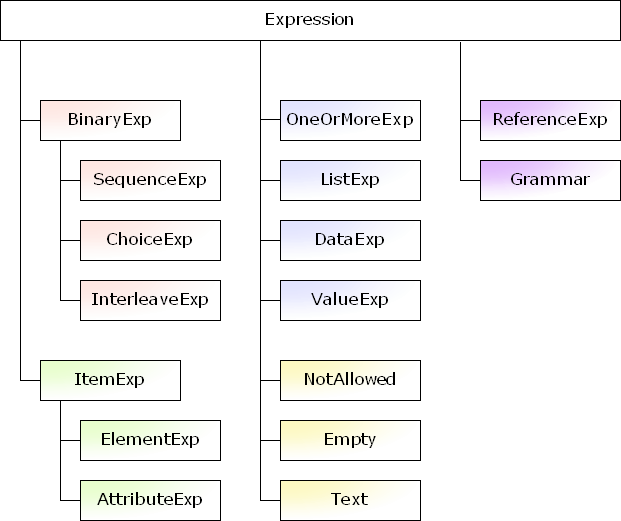
RELAX NG has total of 14 pattern primitives (which I call expressions). You want to model each primitive by a class, all of which are derived from the one base class, which I call the Expression class.
The first category is combinators. All those primitives are binary primitives, so you may want to introduce the BinaryExp class between those classes and the Expression class.
- SequenceExp, which represents the <group> pattern
- ChoiceExp, which represents the <choice> pattern
- InterleaveExp, which represents the <interleave> pattern
The second category is XML items. Those primitives have one content model and one name class. Again, since RELAX NG treats attributes and elements uniformly, you may want to introduce the ItemExp class between those classes and the Expression class.
- ElementExp, which represents the <element> pattern
- AttributeExp, which represents the <attribute> pattern
The third category is miscellaneous unary primitives.
- OneOrMoreExp, which represents the <element> pattern
- ListExp, which represents the <list> pattern
The fourth category is data primitives.
- DataExp, which represents the <data> pattern
- ValueExp, which represents the <value> pattern
The fifth category is special primitives which doesn't have a child nor a parameter.
- Empty, which represents the <empty> pattern
- NotAllowed, which represents the <notAllowed> pattern
- Text, which represents the <text> pattern
The sixth and the last category is used to name patterns.
- ReferenceExp, which represents the <define> pattern
- Grammar, which represents the <grammar> pattern
The following picture describes the entire inheritance hierarchy of these primitives.
 |
Let's look at the detail of each primitives.
These expressions have one child expression and one name class. The child expression represents the content model of an attribute/element, and the child name class represents its tag name (or its attribute name).
These expressions have one child expression. But except that, they don't have much in common.
DataExp has a dattype object, which will validate a string. It also has a child expression that represents the "except" clause of the <data> pattern.
ValueExp has a datatype object and one value object. This datatype object is used to compare the value object with a string literal to see if they are the "same".
Since these expressions have no children and they don't have any parameters, there is no need to create multiple instances of them. Therefore, we'll use the singleton design pattern here. (you just create one instance for each type, and reuse the same instance.)
For a reason that I'll describe later, in fact we MUST use the singleton design pattern.
ReferenceExp has one child expression and a name. One ReferenceExp object is created for each named pattern.
Grammar has (1) one ReferenceExp that represents the <start> pattern and (2) a map from pattern names to ReferenceExps, which allow you to retrieve ReferenceExps by their names.
It also have (3) a parent grammar, which designates its parent grammar. The parent grammar is used to resolve <parentRef> pattern.
Now it's time to implement all those concepts into a bunch of classes. Take your time!
For our validation algorithm, which is yet to be explained, to work quickly, it is critically important to reuse the expression object as much as possible. Look at two figures below. They represents the same grammar (A|B),(A|B)+. As you see, the right figure reuses expressions more than the left figure.
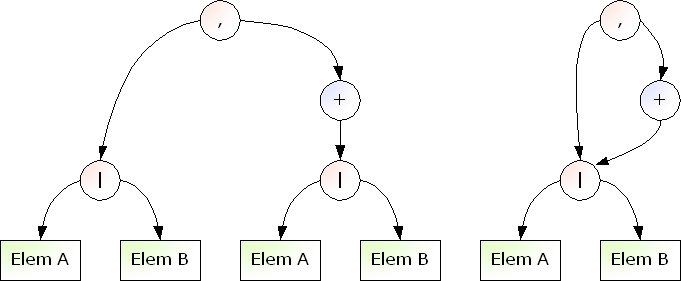 |
For this purpose, we will implement a factory class for expressions. Within this article, I'll call it ExpBuilder.
From now on, nobody but ExpBuilder is allowed to instanciate Expression objects. ExpBuilder will implement a lot of the createXXX methods like this:
Expression createChoice( Expression e1, e2 ); Expression createOneOrMore( Expression e ); Expression createZeroOrMoer( Expression e ); ...
The first step is to make all Expressions immutable. That is, once you create an Expression object, you'll never change its field values. This is necessary because an Expression object can be possibly shared by multiple Expressions, and changing it will cause unexpected side effect.
For example, in Java, you can use the "final" keyword on all fields to make them immutable. If your language doesn't support immutable fields, you have to be careful not to modify them. The following snippet shows the C# version.
Example 1. Modified OneOrMoreExp class (in C#)
public class OneOrMoreExp : Expression {
public readonly Expression child;
....
}
The next step is to create a scheme to reuse expressions. There are many ways to do this, but one way to do is to use a hash table and keep all expressions in it.
For example, you can implement the hashCode method and the equals method for GroupExp as follows:
int hashCode() {
return leftExp.hashCode() + rightExp.hashCode() + 713/*constant_for_group*/;
}
boolean equals( Object o ) {
if(!(o instanceof GroupExp)) return false;
GroupExp rhs = (GroupExp)o;
return this.leftExp==rhs.leftExp && this.rightExp==rhs.rightExp;
}
You have to implement the hashCode method and the equals method correctly for all expressions.
Then you can use the following unify method to "internalize" expressions.
Hashtable h;
Expression unify( Expression e ) {
Expression u = h.get(e);
if(u!=null) return u;
h.put(e,e);
return e;
}
Then the createOneOrMore method would be like this:
Expression createOneOrMore( Expression child ) {
return unify( new OneOrMoreExp(child) );
}
ExpBuilder should perform some of simplification tasks. One of them is <notAllowed/> propagation (4.19 of the spec) For example, abovementioned createOneOrMore method is actually implemented as follows:
Expression createOneOrMore( Expression child ) {
// <oneOrMore><notAllowed/></oneOrMore> => <notAllowed/>
if( child==Expression.notAllowed ) return child;
// other cases
return unify( new OneOrMoreExp(child) );
}
As long as you handle <notAllowed/> correctly, your validator will work correctly.
However, ExpBuilder can do a lot of things to encourage the reuse and thus achive higher performance. For example, you can simplify patterns that contain <empty> pattern.
One of the technique which is frequently used is to make combinators either "left-associative" or "right-associative". If associativity is not enforced, it becomes difficult to detect that two patterns (A,B),C and A,(B,C) are identical. ExpBuilder is an ideal place to set associativity and enforce it.
Another technique, which is also frequently used, is to prevent expressions like A|B|C|A from being created by removing redundant items from a <choice> pattern.
Different implementations adopt slightly different techniques, so you would learn a lot by examining other people's code.
In our core grammar model, we don't have classes for <zeroOrMore> or <optional>. However, it is a good idea to implement the createZeroOrMore method or the createOptional method.
They can be easily implemented by using other expressions:
Expression createZeroOrMore( Expression e ) {
return createOptional(createOneOrMore(e));
}
Expression createOptional( Expression e ) {
return createChoice( e, Expression.empty );
}
Now, you have a (partially) working grammar model. Tomorrow, we'll further extend it to support datatypes.
The corresponding part of the source code of Jing is available here. [1]